Git and GitHub are two of the most used tools in development nowadays. If you've ever installed a library, you've probably done it through Git and GitHub.
Git is a version control system designed for tracking file changes. It was created for allowing multiple people to work on the same project in a non-linear fashion. However, nowadays it is used for much more than that. Some use it as a simple tool to keep their data intact and backed up. Some use it to deploy their projects from their local environments to production since it’s faster and overall more reliable than FTP. Others use it to distribute code through sites like GitHub, and so on.
Regardless of the use case, Git is a necessary skill to learn, which is probably obvious, if you ended up here.
What is GitHub?
GitHub is a distributed revision control system. This means that users are able to store and distribute their projects through GitHub. Really the name says it all, it’s a Hub for Git projects.
Anybody can create a free account on GitHub and start using it. However, all of your Git projects (repositories) will be publicly accessible by default. This means that anybody with your project’s URL can copy (clone) it.
You have the ability to create private repositories (repos for short) if you’re willing to pay $7/mo, but don’t worry. If you’re just trying to learn and still use private repos, you can use BitBucket, which provides this feature for free.
For this tutorial’s purpose, we’re going to use GitHub, because that’s where all the JS and CSS libraries and frameworks live. But keep in mind that we’re learning how to use Git, not GitHub or BitBucket. All of the commands work on both platforms, since they both use Git.
Installing Git
On MacOS
In MacOS, you can use Homebrew to install it. If you don’t have Homebrew installed, it’s as easy as opening up a Terminal window and copying the following command in:
A successful installation would return a message similar to the following:
git version 2.7.0
On Linux
Installing Git on Linux is as simple as installing anything through your distribution’s package manger.
Debian / Ubuntu: sudo apt-get install git
Redhat / CentOS: sudo yum install git
Arch Linux: pacman -S git
If your Linux distro doesn’t have a package manager, you can also install it through the official site: git-scm.com.
On Windows
On Windows, you can install the official Git tool from git-scm.com. Click the Download button and install it as you would any other program.
After the installation is done, run the Git Bash program.
Basic Functionality
How Git Works
Repositories
A Git project is called a repository. Most people call it “repo” for short. We’re going to call it a “repo” in this tutorial too. A Git repo is a collection of history steps which contain your file edits. Every time you upload something to the repo, you create a step in history.
What makes Git so powerful is its ability to manage those history points. You can reset your code base to any point, which will delete all of the points which came after it, or you can revert only certain points from the code base.
Every time you reset to a point or revert a point, Git knows how to actually remove only the updated code from all the files in those points. If it reaches a point where it doesn’t know how to do it automatically, it will create a “conflict”, which you’ll have to fix manually. This usually happens when 2 or more people work on the same file and edit a line of code that’s common in both history points. Don’t worry if you don’t understand this yet, it will all make sense later.
Commits
The “history points” that we were just talking about in the previous section, actually have a name, they’re called commits. Therefore, a repo is a list of commits which you can control by resetting or reverting.
Typical Workflow
A typical workflow refers to creating a commit and uploading it to the repository.
To do this, we usually do 4 things:
Select the modified files that we want to submit.
Commit them locally.
Pull (download) the previous commits that might have been created while we were working.
Push (upload) our changes to the repository.
Now that we have some idea of how Git works, let’s see how it looks like in action.
Creating a Git Project
Initialization
The initialization of a Git project is done locally. I highly encourage you to follow along and play with every command until you understand what it does and it makes sense to you.
We enter the dir that we want to use Git on
cd my-project
And run the following command:
git init
The output should be something similar to:
Initialized empty Git repository in /Users/gecko/Web/Code/tutorials/git-tutorial/.git/
That newly created .git directly is used as a local database by Git to know what’s in the repository. You don’t need to learn what’s actually inside, just know that if you remove it, you’re going to lose all of the file changes that you haven’t pushed to the repo yet.
Creating a Repository
This is where sites like GitHub and BitBucket come in handy. To create a repository in GitHub, assuming you have an account and you’re logged into it, you click the + icon at the top and select “New repository”.
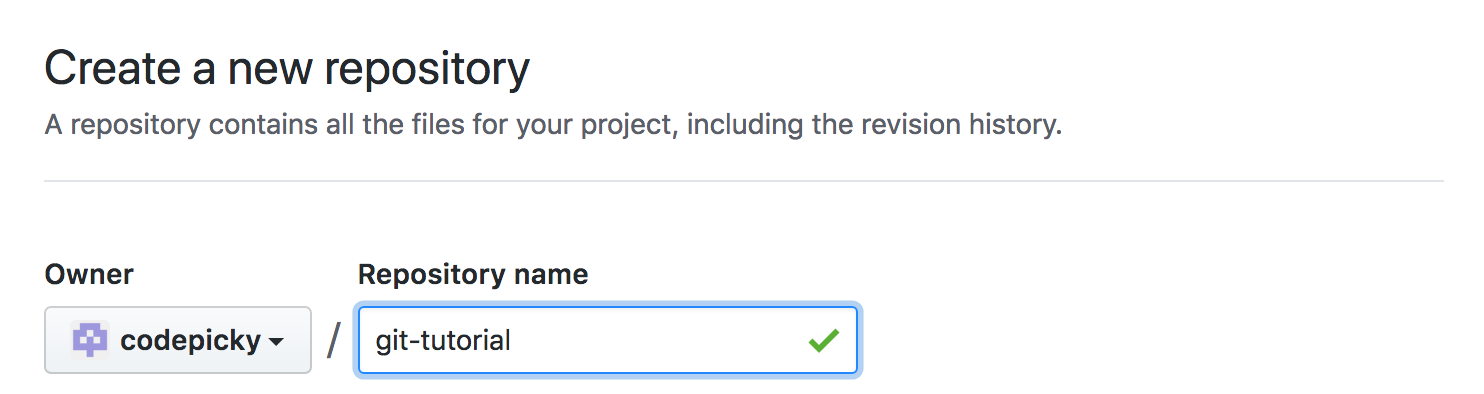
On the new page, simply fill in the name of your repo and click “Create repository.”
The green check mark will attest that the name is unique on your account. You can’t use the same name for 2 different repos because they are used to create the URL which points to the repo, which needs to be unique.
The repo’s URL is: github.com/[owner]/[repo-name]
So, in my case, the repo’s URL is: https://github.com/codepicky/git-tutorial
Try visiting it, it works!
Linking the Repository to Our Git Project
GitHub already provides instructions on how to do this when you create the repo, but we’re going ignore them for now, in order to delve a little deeper into how they work.
Adding an Origin
An origin is what Git calls a source. It’s basically the address to where the project files will live at.
To add an origin to any Git project, we use the “remote” command of Git, which supports the parameters <command> <name> and <url>. The complete command is:
git remote <command> <name> <url>
To view your repo’s origin URL, go to the repo’s via its official URL, the one resembling https://github.com/codepicky/git-tutorial, and copy the SSH address.
In my case it will be:
The command will not return anything after you run it, because it simply copies it inside the .git/config file.
Adding an origin typically only happens once, the first time you setup the repo locally. From now on, that link is going to live on the .git/config file, so there’s no need to add it again.
Selecting Files
Now, as per the typical workflow explained before, the first step when we want to send something to the repo is selecting the files. Git calls the process of selection “staging”. We need this process of staging in order to perform actions on these files later. Because we might want to do different things to different files.
We do this using the Git add command. The command will select all files recursively if you specify a directory.
But before selecting, we need to know which files have been modified. To list the modified files, run:
git status
If your directory is empty, you’ll see a message like this returned:
nothing to commit (create/copy files and use "git add" to track)
If your directory is not empty, you’ll see a list of all your files.
For those of us who have empty directories, let’s create a file just to see how git status looks like when we have modified files.
I’ll create a file called README.md and write “# Git & GitHub Tutorial” inside.
Now let’s run git status again. This time we should see README.md listed. And we do, under “Untracked files”.
By untracked files, Git refers to files which have been edited and are not part of the repo yet.
So let’s fix.
Let’s assume we want to stage (select) all untracked files, even if I only have one.
Running the following command will stage all files under .:
git add .
The dot means “current directory”, and as we now know, git add will attempt to stage all untracked files under the given directory.
As a result, if we run git status again, we’ll see that our files are now listed under “Changes to be committed.”
Tip: Anytime you find yourself lost in the process, simply running git status can give you an idea of what you wanted to do.
Creating a Commit
The next step is to create a commit. We do this using the Git commit command:
git commit -m 'The message for this commit.'
That command supports the -m option which allows you to specify a message for the commit. This is useful when you want to look over all the commits later and see when you added something, or what to revert or reset to.
Tip: Try to always set a descriptive message. I know that sometimes is hard to come up with descriptions for everything, but it will come in handy later.
To commit my README.md file, I’m going to run:
git commit -m 'Added the readme file.'
This is going to return something similar to this:
The first line lists the identifiers for the new commit, “master” is the branch name (we’re going to talk about branches a bit later), “fc08a39” is the first 7 chars of this commit’s SHA1 hash, which every commit has, and next to that is our comment.
Next, we’re going to see a summary for the files in that commit. We see that 1 file changed and there was 1 line inserted.
Below that, we’re going to get a list of every file that was created, modified or deleted. In my case, there’s only one.
Pushing Our New Commit
Up until now, all that we’ve done is saved only locally. We haven’t sent anything to GitHub yet. Uploading something to GitHub is called “pushing” in Git terminology.
To push something, we use the Git push command. Try to run:
git push
If you’ve got the following message back:
[email protected]: Permission denied (publickey).
fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists.
We’re going to take a short break to talk about Authentication.
Authentication
To protect our repos from being accessed by anybody, we need to have some kind of authentication happen before we can write to a repo.
We have two choices here. We can use the HTTPS version of our origin URL, and we’ll need to enter our password every time we push to our repo. Or, we could use an SSH key.
To use the first option, simply use that as the origin URL. You can specify it when using the git remote add origin <URL> command, or you can update it directly in the .git/config file inside your project’s dir.
To use the second option, authenticating through SSH keys, follow the instructions.
Generating an SSH key
Run the following command in a Terminal or Git Bash instance:
This creates a new ssh key, using the provided email as a label.
When you’re prompted to “Enter a file in which to save the key,” press Enter. This accepts the default file location.
When asked for a passphrase, you can enter a password, but you also have the option to enter none. If you don’t share your key with anybody, the password isn’t necessary.
Now you should have a file in ~/.ssh called id_rsa.pub.
Installing the new key on your GitHub account
The generator created 2 keys, one private and one public. In order for this to work, you need to tell GitHub your public key.
Go to your SSH and GPG keys page inside your GitHub account at the following address: https://github.com/settings/keys or click your profile picture > choose Settings > choose SSH and GPG keys.
Press “New SSH key”.
Give it a title to recognise it later. I called mine Laptop, to know which machine it is.
List your public key file with the following command in a Terminal or Git Bash instance:
cat ~/.ssh/id_rsa.pub
Copy the contents into the Key field in your GitHub account (it should start with ssh-rsa and end in your email) and press “Add SSH key”.
Now you’ve installed the key into your GitHub account.
Let’s try again the push command. Return to your project in Terminal or Git Bash and run:
git push
The authentication worked, but you might get this message.
No refs in common and none specified; doing nothing.
Perhaps you should specify a branch such as 'master'.
error: failed to push some refs to '[email protected]:codepicky/git-tutorial.git'
This is because we don’t have a branch pushed yet. We’re going to talk about branches later, but for now, let’s initialize one. Let’s run:
git push -u origin master
This command specifies the branch name that we want to push the code to. It’s not required every time you do a push, but it is required for the first time.
Now we should be able to see the code on our repo’s public URL: https://github.com/codepicky/git-tutorial
Indeed, there is a README.md file in there with a message next to it, which is our commit message.
Congratulations! You’ve done your first successful push.
Note
You don’t have to push after every commit. You can have as many commits locally as you want. Nobody forces you to push them, but if you want to have them live, and available to other users, you need to push them every once in a while. The advantage to leaving them locally longer is that if you decide to get rid of an entire commit, you can, without it reaching the repo and messing things up.
Hopefully, you can already see how this process can be very useful in development since your changes are all grouped together in commits. If you provide them with a useful message every time, even better.
Cloning
Cloning a repo means downloading it while at the same time initializing the git repo. You can’t clone a repo into a directory that has files already. You need to do it in a fresh empty directory.
Cloning is as easy as running:
git clone <repo URL>
For example, if you wanted to clone my repo, you would create a new directory, cd into it from a Terminal or Git Bash and run:
That will clone my repo into a new dir called my-project.
Pulling
The process of downloading what’s in the repo, once you have the repo setup, is called pulling.
When working with others on a project, you will run into situations where others have pushed something to the repo before you, and when you try to push your commits, it will result in an error saying that your commits have been pushed successfully, but the push failed because you don’t have the last live commit locally.
To solve this, you simply run git pull, to fetch the new commits in, then run again git push.
Merge Conflicts
The process of combining the changes with the already existing files in the repo is called merging in Git terminology and it’s done automatically. But, sometimes, when 2 or more people (or even 2 different initializations of the same project) work on the same lines of code in the same file, Git becomes confused as to which lines to consider and which to delete.
It doesn’t know if it should keep both, discard one or even which to discard. So, it creates what’s called a “merge conflict” which needs to be solved manually.
Example scenario
Alice clones the repo on her computer and adds a new line to the README.md file. She stages the file, creates a new commit and pushes it to the repo.
Bob already had the project initiated on his computer, but he didn’t pull the latest changes yet, so he assumes that nobody else is working on README.md and proceeds to add a new line as well. He stages the file, creates a new commit, but when he tries to push it, Git fails with the following error:
To [email protected]:codepicky/git-tutorial.git
! [rejected] master -> master (fetch first)
error: failed to push some refs to '[email protected]:codepicky/git-tutorial.git'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull …') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
This error means that you cannot push before having all the other changes locally. And this is because when you pull, Git will try to merge the changes coming from the repo to yours that you have locally. This may not seem critical, you might think that you should be able to push your commit and get the other stuff later. But consider what happens to Bob when he does a git pull:
remote: Counting objects: 3, done.
remote: Total 3 (delta 0), reused 3 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), done.
From github.com:codepicky/git-tutorial
fc08a39..6bed7de master -> origin/master
Auto-merging README.md
CONFLICT (content): Merge conflict in README.md
Automatic merge failed; fix conflicts and then commit the result.
As you can see, it is only at this stage that the conflict appears, which means that pulling before pushing is in fact critical, otherwise this merge would not have been possible to fix at any other step of the process.
Now, because Bob got the conflict, he is forced to fix it before trying to push again.
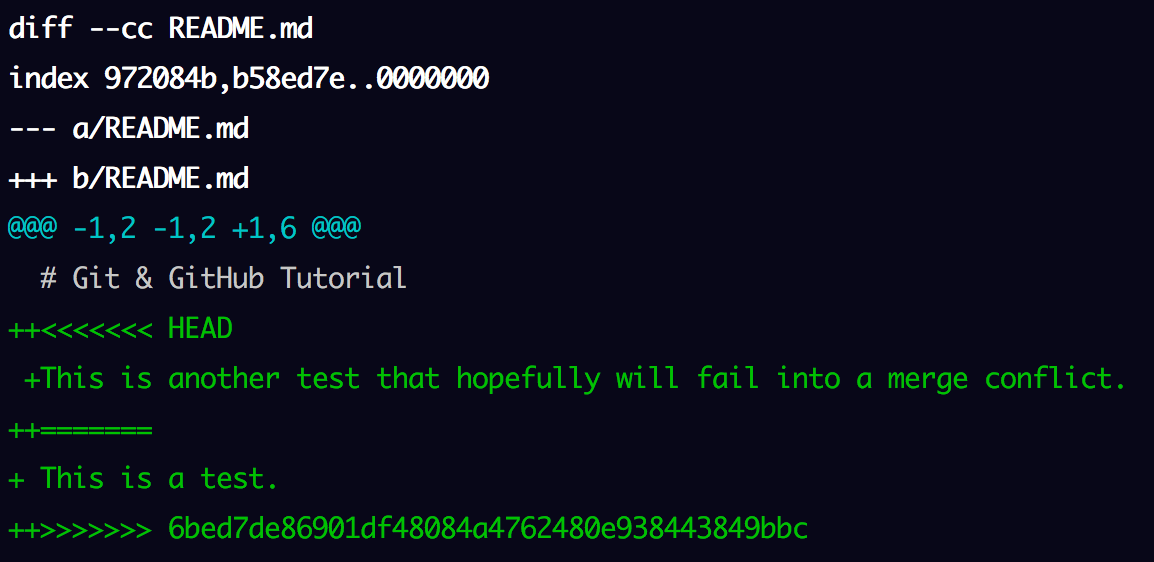
If he runs git diff README.md, his file will open in Git’s integrated diff tool which will show where the conflict happens:
<<<<<<< HEAD represents the beginning of Bob’s version of the part of the file in conflict. Between ======= and >>>>>>> 6bed7de86901df48084a4762480e938443849bbc we see Alice’s version of the file. Bob needs to edit the file to choose the version that should stick.
So, he edits the file to read:
# Git & GitHub Tutorial
Ignore this: Just fixed a merge conflict.
Because, of course, he had the option to choose none of the versions and add a new one. Now, when he runs git status, he will see:
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: README.md
Which he needs to stage & commit again. Then he’s free to push.
Branches
Branches are ways to diverge from the code base to continue development on something that shouldn’t mess with the mainline.
They are often used for 2 things:
As feature branches, meaning that you are able to develop something that might not be done very soon. You can test it out in that separate branch until you consider it ready to get into the mainline.
As dev branches, meaning that every dev has their own branch which nobody else messes with. This practice is used to keep things a little more organized in a team.
Creating Branches
To create a branch out of the current one, use the command:
git branch <name>
For example:
git branch test-branch
Will create a branch called test-branch. To switch to it, use:
git switch test-branch
Now that we’re on the test-branch, let’s do something with it. For example, let’s delete the README.md file. Let’s then stage, commit and push it.
Now, see what happens when we come back to the mainline branch, master.
$ ls
$ git checkout master
Switched to branch 'master'
Your branch is up-to-date with 'origin/master'.
$ ls
README.md
$ cat README.md
# Git & GitHub Tutorial
Ignore this: Just fixed a merge conflict.
As we can see, the README.md is still there. And this is part of the magic of Git. We deleted the file in one branch, but the file is still there in the others.
Merging Branches
Once you have some changes ready in a branch, you can merge it with another branch. When merging a branch B into branch A, Git computes the difference between the two and adds the missing commits from B to A. Let’s create a branch to see this in action.
$ git branch add-new-file
$ git checkout add-new-file
Switched to branch 'add-new-file'
$ echo 'This is just a new file.' > new.file
$ git add .
$ git commit -m 'Added the new file.'
[add-new-file 2eaed1c] Added the new file.
1 file changed, 1 insertion(+)
create mode 100644 new.file
$ git checkout master
Switched to branch 'master'
Your branch is up-to-date with 'origin/master'.
$ git merge add-new-file
Updating d9ed601..2eaed1c
Fast-forward
new.file | 1 +
1 file changed, 1 insertion(+)
create mode 100644 new.file
$ git status
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
nothing to commit, working directory clean
$ git push
Counting objects: 3, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 342 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To [email protected]:codepicky/git-tutorial.git
d9ed601..2eaed1c master -> master
Pushing a branch
By default, branches are only stored locally. If you want to push a branch to the repo, you can do it in the same manner as we’ve done for commits. You commit something, then use the command:
git push -u origin <branch-name>
Here’s an example:
$ git checkout add-new-file
Switched to branch 'add-new-file'
$ git push -u origin add-new-file
Total 0 (delta 0), reused 0 (delta 0)
To [email protected]:codepicky/git-tutorial.git
* [new branch] add-new-file -> add-new-file
Branch add-new-file set up to track remote branch add-new-file from origin.
Reverting a Commit
To revert a commit, you use the revert command as such:
git revert <commit hash>
To find the hash, you first need to list all the commits with:
git log
Then you choose the hash and run the revert command.
This will revert a commit by creating another commit that reverses the code changes. It will ask you for a new commit message. All you have to do after reverting a commit is to push the changes.
Resetting to a Commit
You can reset to a previous commit by using:
git reset <commit hash>
To see the commit hashes along with their messages, run:
git log
The log command lists all the commits in the current branch.
By default, the reset command will remove the commits and keep the modified files as untracked files, just in case you want to revisit them. If you don’t want to keep them, use:
git reset --hard <commit hash>
Stashes
Stashing is a ways of storing code in a separate place, when you have modified files but you don’t want to commit them yet. It’s not deleting the changes, but it’s not committing them either.
When stashing some changes, they will not display in git status anymore, they just exist in their separate “stash,” somewhere under .git. You mgith ask: Well, then what’s the point? The point is that you can return to them later, when you do want to use them. You can “apply” them back to the code.
Stashing something:
git stash save 'Message'
Right now the changes are gone. To bring them back, you list all the stashes with:
git stash list
And get the id before : of the stash that you want to apply back.
For example, to reset the first stash, you run:
git stash apply 'stash@{0}'
Tags
Tags are ways of naming a place in the commit list. They’re often used for specifying an application’s version. For example, after a certain commit you might want to say that a specific commit is the point where version 1.0.0 was done. Anything that shows up afterwards, is going to be part of another version of the app, that way, when somebody wants to limit your application code to version 1.0.0, they can, through tags.
To create a tag, you simply run:
git tag -a 'v1.0' -m 'Message.'
The -m 'Message' is optional, but that’s how to register a tag.
Now, when you run:
git tag
You’ll see a list of all your defined tags.
If you want to inspect a particular tag, you run:
git show v1.0
Conclusion
I hope you now understand why Git is so popular, and how it can help yourself develop faster and more reliable code. If you have any questions, feel free to post a comment below and I’ll be happy to help you.


2 Replies to “How to Use Git and GitHub”